Introduction to Neurons
This chapter is mainly divided into two sections. The first Section «Click Here» presents a few motivating examples that work similarly to artificial neurons. The mathematical formulation of artificial neurons is then provided in the second Section «Click Here», and the reason behind the name neuron is made clear by comparing the formulation with the functionality of biological neurons. The chapter ends with an outline of the algorithm to learn a neuron model.
Motivating Example
In this we give two simple examples to set a fundamental idea behind the way artificial neurons are formulated. The first example is intuitive from physics that illustrates an important and commonly used activation function called rectifiable linear unit (ReLU) and another from electric circuit which involves the step function as the activation function which is fundamental in defining perceptrons.
Water Source-Sink Control Problem
Calin, Ovidiu, Deep Learning Architectures: A Mathematical Approach, Springer, 2020.
Mathematical Problem
The task is to adjust the knobs and the rate of outlet, depending on the inlet water pressure, such that the volume of water in the tank after time \(t\) is exactly at \(V\).
The problem can be posed mathematically as follows: Given \(V>0\), \(t>0\), and the vector \(\boldsymbol{P} = (P_1, P_2, \ldots, P_n)\), for \(P_i> 0\), find a vector \(\boldsymbol{w} = (w_1, w_2, \ldots, w_n)\) and \(R>0\) such that
The mathematical problem posed above takes \((\boldsymbol{P},V)\in (0,\infty)^n \times (0,\infty)\) as an input and provides \((\boldsymbol{w},R)\) as an output. Often the interest is to obtain one set of parameters \((\boldsymbol{w}^*,R^*)\) such that
for all \((\boldsymbol{P},V)\in \mathcal{D},\) where
is a given finite dataset. Further, it is desirable to obtain an optimal pair \((\boldsymbol{w}^*,R^*)\) that best fits the given dataset.
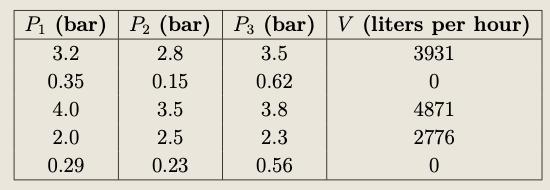
Given \(t=1\) hour and the outlet flow rate is \(R=450\) L/h, determine the weight vector \(\boldsymbol{w} = (w_1, w_2, w_3)\).
Electric Circuit
Calin, Ovidiu, Deep Learning Architectures: A Mathematical Approach, Springer, 2020.
Click here to see the details of the book
Mathematical Problem
The problem we are interested in the present example is similar to the one posed in the above example.
Given a dataset \(\mathcal{D} = \{(\boldsymbol{x}^{(k)}, y^{(k)})~|~k=1,2,\cdots, N\} \subset \mathbb{R}^n \times (0, \infty)\), the problem of interest is to find the weights vector and bias \((\boldsymbol{w}^*, \beta^*)\) such that
Linear Regression
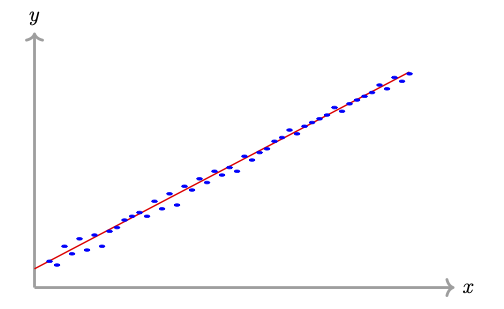
Linear regression is one of the most fundamental and widely used methods in both statistics and machine learning. It aims to model the relationship between a dependent variable and one or more independent variables by fitting a linear equation to the observed data.
In linear regression, the given dataset consists of
where \( \epsilon \) is the error term, representing the deviation of the observed values from the true values.
An illustration for the case \(n=1\) is depicted in the following figure:
Mathematical Problem
Let us give a precise formulation of a linear regression model.
For the given dataset
the primary objective is to find the values of the coefficients \((w_0, w_1, \ldots, w_n)\) such that the sum of the squared errors is minimized.
In other words, we aim to minimize the sum of squares error function
where \(\overline{\boldsymbol{w}}=(w_0, w_1, \ldots, w_m)\) is the regression coefficient vector. That is, to find the optimal coefficient \(\overline{\boldsymbol{w}}^*\) such that
The optimal coefficients best fit the given dataset in the least squares sense and this method is known as the least squares method.
Artificial Neurons
The physical problems discussed in Section «Click Here» resemble the mathematical framework of an artificial neuron involving weights (control knobs and resistors), a bias term acting as a threshold (like the outflow rate and flow of current to ground), and a nonlinear activation function.
Mathematical Formulation
We now formalize the physical intuitions through the mathematical definition of an artificial neuron.
An artificial neuron is a tuple \( (\overline{\boldsymbol{w}}, \mathscr{A}) \), where
- \(\overline{\boldsymbol{w}}=(w_0, \boldsymbol{w})\in \mathbb{R}\times \mathbb{R}^{n}\) is the augmented weights vector, with \(w_0=b\in \mathbb{R}\) as the bias and \(\boldsymbol{w}=(w_1,w_2,\ldots,w_n)\in \mathbb{R}^n\) as the weight vector; and
- \(\mathscr{A}:\mathbb{R}\rightarrow \mathbb{R}\), is an (nonlinear) activation function.
For a given \(\overline{\boldsymbol{w}}\), the right hand side function is the composition of the affine function \(\text{𝕒}: \{-1\}\times \mathbb{R}^n\rightarrow \mathbb{R}\) given by
and the activation function \(\mathscr{A}\). We define the neuron function (or the primitive function) \(\text{𝕗}:\{-1\}\times \mathbb{R}^n\rightarrow \mathbb{R}\) as
A schematic diagram of an artificial neuron is depicted in the following figure.
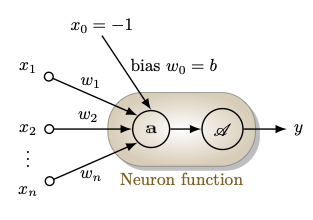
An artificial neuron can be viewed as a special case of a single-layer neural network with just a single output unit.
Calin, Ovidiu, Deep Learning Architectures: A Mathematical Approach, Springer, 2020.
Click here to see the details of the book
Note the notational differences between our definition above and the definition given in the book. For the examination point of view, students are requested to follow the notations used in our notes.
- The water supply problem discussed in Section «Click Here» can be viewed as an artificial neuron \((\overline{\boldsymbol{w}}, \texttt{ReLU})\), where
\[ \texttt{ReLU}(x) = \max\{0, x\}, \]
and the bias \(b\) is the outflow rate \(R\).
- The electric circuit problem discussed in Section «Click Here» can also be viewed as an artificial neuron \((\overline{\boldsymbol{w}}, H)\), where \(H\) denotes the Heaviside function given by
\[ H(x) = \left\{\begin{array}{lc} 0,&\text{if}~x<0\\ 1,&\text{if}~x\ge 0 \end{array}\right. \]
An artificial neuron with Heaviside function as the activation function is called the perceptron. We will discuss perceptrons in more details in Section «Click Here».
Comparison with Biological Neurons
The mathematical definition of \(\text{𝕗}\) (given in Definition «Click Here» ) is named as neuron by taking the inspiration from the biological neurons in brains. To have a clear understanding of these two concepts, we briefly understand the structure and the functionality of biological neurons in brains and then make a comparison with the artificial neuron formulation.
From the Definition «Click Here» on artificial neurons, we see that an artificial neuron includes a simple mathematical function (neuron function) with inputs, weights, bias, activation function and output. On the other hand, a biological neuron is a specialized type of cell in the nervous system with dendrites, soma, axon, and synapses. Biological neurons are responsible for transmitting and processing information through electrical and chemical signals.
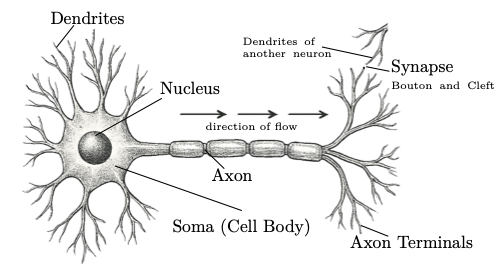
A typical neuron has four main parts (shown in the above figure):
- Dendrites: Branch-like structures that receive input signals from other neurons in the form of chemical signals, specifically neurotransmitters.
- Soma (Cell Body): Contains the nucleus and most of the cell's organelles where input signals (electrical impulses) are integrated and a nonlinear threshold is applied. If the combined input exceeds this threshold, the axon hillock triggers an action potential, which is then propagated down the axon.
- Axon: A long projection that transmits electrical signals from the soma to other neurons. The axon terminal of one neuron connects to the dendrites of another neuron via synapses.
- Synaptic Boutons: These are the small, bulb-like endings of axon terminals that are involved in transmitting signals to other neurons. When an electrical signal (action potential) reaches a synaptic bouton, it triggers the release of chemical messengers called neurotransmitters into the synaptic cleft, which is a tiny gap between the axon terminal and the dendrite of the next neuron. Electrical signals cannot cross this gap directly, so neurotransmitters are used to carry the signal across.
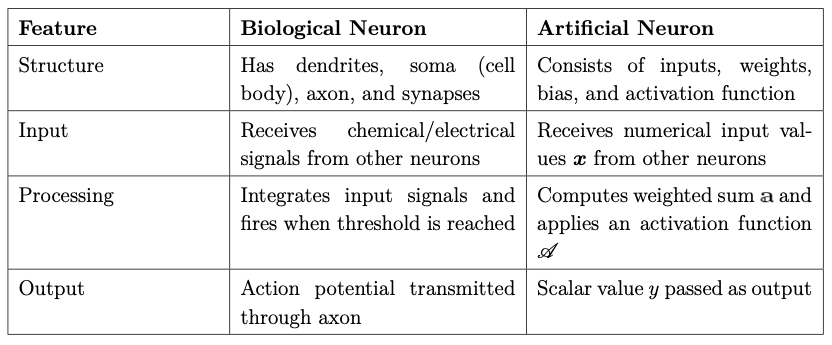
A comparison between biological neurons and artificial neurons is summarized in the above table. As we can see, biological neurons are more complex in nature, whereas artificial neurons are simplified mathematical models that only resemble biological neurons. Artificial neurons are not intended to be accurate models of biological neurons. Rather, they are designed to mimic certain features, such as signal integration and nonlinear activation, to build systems capable of performing tasks through self-learning, giving rise to artificial intelligence.
A neuron can connect to many other neurons through its axon terminals, and similarly, it can receive inputs from several neurons via its dendrites, forming a biological neural network. Similarly, multiple artificial neurons can be connected through layers to form an artificial neural network, which we will discuss in a later chapter.
- \(x_1\): Smell intensity (scale 0-10; mango juice has a stronger smell),
- \(x_2\): Color richness (scale 0-10; varies between orange and yellow),
- \(x_3\): Pulp density (scale 0-10; mango juice is thicker).
Model Mrs. Sahana's decision-making using an artificial neuron by indicating appropriate parameters and the activation function, but describe its working using the terminology of biological neurons as follows:
- The sensory inputs arrive at the neuron's dendrites.
- Each input is modulated by a corresponding synaptic weight.
- These weighted signals are summed in the cell body and combined with a bias, representing the neuron's threshold.
- If the total input exceeds a threshold (modeled by an activation function), the neuron fires an action potential.
Supervised Learning: An Overview
The mathematical formulation of a neuron (AN) takes \(\boldsymbol{x}=(x_1,x_2\ldots,x_n)\in \mathbb{R}^{n}\) as input and computes the output \(y\in \mathbb{R}\) as the value of the neuron function \(\text{𝕗}\). A complete AN model for a given problem therefore involves a well-defined neuron function, which in turn includes three choices, namely,
- the dimension of the input vector \(n\);
- a suitably chosen activation function \(\mathscr{A}\); and
- a fixed choice of the bias and weights \(\overline{\boldsymbol{w}}=(b,\boldsymbol{w})\in \mathbb{R}\times \mathbb{R}^{n}\).
The process of obtaining \(\overline{\boldsymbol{w}}=(b, \boldsymbol{w})\) is referred to as learning a model (or training a model) from a given dataset \(\mathcal{D} \subset \mathbb{R}^{n} \times \mathbb{R}\) of the form
where \(\boldsymbol{x}_k\in \mathbb{R}^n\) is an input vector (also called a feature vector) and \(y_k \in \mathbb{R}\) is the corresponding output or label. The dataset \(\mathcal{D}\) is called a labeled dataset, and each point \((\boldsymbol{x}_k, y_k)\) in \(\mathcal{D}\) is called an example or a training sample.
Learning from such a labeled dataset is called supervised learning, where the goal is to approximate a function (or a model) that maps inputs \(\boldsymbol{x}_k\) to outputs \(y_k\).
A general outline of the learning procedure is as follows:
Here, \(\mathcal{D}_\text{train}\) is the training set, \(\mathcal{D}_\text{test}\) is the test set, and \(\mathcal{D}_\text{val}\) is the valudation set. Typically, \(\mathcal{D}_\text{train}\) contains a significantly larger portion of the data, often at least 70% of \(\mathcal{D}\), selected randomly in an unbiased manner. Let us use the notation
where \(N_\text{train} = \#(\mathcal{D}_\text{train})\).
For instance, a commonly used cost function is the mean squared error
where \(\mathscr{A}\) is the activation function of the neuron.
An optimization method such as the gradient descent method is used to compute \( (b^*, \boldsymbol{w}^*) \). This step is called the training step or learning step.
Once the optimal parameters are computed by minimizing the cost on the training data, we typically say that the model is trained.
Regularization generally includes fine tuning some key parameters, referred to as hyperparameters. The validation set \(\mathcal{D}_\text{val}\) is used to tune hyperparameters.